
記事の要約:単変量線形回帰モデルと図のつくり方【図解】
この記事で学べること
- 線形回帰モデルとは?
- statmodelsライブラリによる線形回帰モデルを用いた解析方法
- seabornライブラリによる線形回帰モデルの結果の図示化
- scikit learnライブラリによる線形回帰モデルを用いた解析方法(おまけ)
この記事のまとめ
- 線形回帰モデルとは連続尺度の結果変数を説明変数で説明(予測)するモデル
- statmodelsを使えば結果の表示まで簡単にできる
- 単変量線形回帰モデルであればseabornを使えば結果の図示化が簡単にできる
線形回帰モデルとは?
線形回帰モデルとは,連続尺度の結果変数を説明変数で説明(予測)する統計モデルのことです.このとき,説明変数は複数あっても大丈夫なのですが,まずは簡単のために「説明変数が1つだけ」の状況を考えます.これが「単変量」線形回帰モデルと呼ばれるもので,以下の式で表すことができます.(※単変量や単変数は厳密には定義が異なるのですが,ここでは便宜的に単変量といいます)
$$ Y = \alpha + \beta X + \varepsilon $$
ここでは数学的に細かいお話は省きますが,上記の説明変数Xに係る係数βが,説明変数Xの影響力を表していると考えてください.このβは「説明変数Xが1増加したときに結果変数Yがβだけ変化する」という風に解釈することができます.また専門用語では「回帰係数」と呼びます.
つまりXとYの関係を直線の傾き具合βで表現していて,データからこの傾き具合βを推定することが一つの目的であると考えてください(※実際には説明変数Xのデータの尺度や扱い方によって色々な表現ができますがここでは理解を進めることを優先しています).ちなみにαは切片項(Xが0の時のYの値),εは誤差項というのですが,これらもβと同時に推定されます.今はとりあえず無視してください.
なにはともあれ,まずは実際にYとXの関係について,線形回帰モデルを使ってみてみましょう!
事前準備:データのダウンロード
それでは早速データセットを読みこんで解析していきましょう.
python,Anaconda3をインストールした際に使えるようになるSpyderという環境で操作します.Python単体でも同様のスクリプトで実行可能ですが,Spyderにはいろいろな補助機能があるため,こちらを使っていきましょう.
データセットは練習用のCSVデータを準備しましたので,手元にちょうどよいデータがなければ,これらをダウンロードしてご利用ください.
| id | iv | cnf1 | cnf2 | ・・・ | outcome_num | outcome_skew | outcome_ord | time |
| 1 | 0 | 0.14 | 0 | ・・・ | 200.9 | 0 | 1 | 0.04 |
| 2 | 0 | 0.41 | 1 | ・・・ | 160.37 | 0 | 1 | 0.11 |
| 3 | 1 | -0.07 | 0 | ・・・ | 461.07 | 158.34 | 3 | 0.08 |
| 4 | 1 | -0.25 | 0 | ・・・ | 363.76 | 76.03 | 2 | 0.02 |
| 5 | 0 | 0.7 | 0 | ・・・ | 290.58 | 0 | 1 | 0.02 |
| ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ |
| 496 | 0 | -1.35 | 1 | ・・・ | 227.81 | 0 | 1 | 0.11 |
| 497 | 0 | 1.03 | 0 | ・・・ | 170.44 | 0 | 1 | 0.17 |
| 498 | 1 | -0.81 | 0 | ・・・ | 326.61 | 44.92 | 2 | 0.2 |
| 499 | 1 | 1.8 | 0 | ・・・ | 256.07 | 0 | 1 | 0.13 |
| 500 | 0 | 1.77 | 0 | ・・・ | 197.09 | 0 | 1 | 0 |
※11人目以降は省略
準備1.参考データ(CSV)をダウンロード
※後ほどSpyder上で読み込みたいデータの場所を指定する必要があるため,デスクトップなど自分が分かりやすい場所に保存しておくことをおすすめします!
準備2.Spyderを起動 ⇒ 新規ファイルを作成 ⇒ CSVファイルの読み込み
CSV・Excelファイルのpythonにおける読みこみ方は,以下で詳しく説明していますので,参考にしてみてください.今回はデータセットを df と名前をつけて読みこんでいます.
# pandasライブラリをpdを名前をつけて使える状態にする
import pandas as pd
# pdに含まれるread_csvというメゾッドを使ってデータを読みこみdfとして保存
# データの格納場所は適宜修正してください
df = pd.read_csv("/Users/USERNAME/Desktop/robustwife/robustwife_all.csv", encoding="utf-8") 
statmodelsライブラリで線形回帰分析
線形回帰モデルが扱えるライブラリは沢山ありますが,解析から結果のまとめまでが全て簡単に行えるstatmodelsライブラリを今回は紹介します(公式).statmodelsライブラリは,回帰モデル全般を扱うことができるライブラリで,実際の解析でも非常に重宝しています.
線形回帰分析をpythonで実行する
statmodelsライブラリで線形回帰分析を行う際には ols 関数を使います.ols関数においては結果変数と説明変数をそれぞれ指定する必要がありますが,その方法は2通りあります.1の方法がより直感的かつ,変数を抽出するステップなどを省略できますので,今回は1の方法を採用します.
- “結果変数 ~ 説明変数” という式 + 利用するデータセット名(dfなど) を入力する
- 結果変数と説明変数をそれぞれデータセットから抽出してから入力する
# statsmodelsライブラリを使える状態にする
import statsmodels.formula.api as smf
# モデルの構築ols(目的変数Y~説明変数X)
# データセットは df と名前を付けて保存しておいてください
results = smf.ols("outcome_num ~ treat_num", data=df).fit()
# 出力
results.summary()
上記を実行してもらえれば,線形回帰モデルの結果が results に保存されます.resultsの内容を要約して表示するために result.summary() と入力しています.結果がひとめに分かるようになりましたね.
今回は treat_num という説明変数が outcome_num という結果変数にどの程度提供を与えていたのかを検討する際には,treat_num 行の coef 列を見てください.ここに記載されている24.6という数値が treat_num の回帰係数(つまりこれが回帰係数β = coefficient)の推定値です.つまり「treat_num が1上昇したときにoutcome_numが24.6上昇する」という風に理解できます.
またその際の95%信頼区間も同時に表示されますが,これは(かなりざっくりというと)推測のばらつき具合を表していると考えてください.線形回帰モデルではこの区間が 0 を含まなければ,「統計学的に有意な差である」と考えることができます.(回帰係数βが0ということは,説明変数が変化しても結果変数は全く変化しない = 説明変数と結果変数は(線形には)関連していない,という理解をしてもらうと良いかと思います.)
また同様に treat_num 行の P>|t| 列には,この回帰係数βの推定値が0と異なるかどうかを検定したときのp値が記載されています.このp値が一般的に0.05未満であれば,統計学的に有意に回帰係数βの推定値が0とは異なるということが言えます.
※この0.05という基準を有意水準と呼びます.本来はこの値は適切な事前計画がなされている場合に意味のあるものとなるのですが,ここでは一旦細かい話は省略して,一般的な解釈に留めておきます.
線形回帰分析で推定した結果を図で俯瞰する
上記までの結果のように,数字だけで示されても,どのような結果が得られているのかいまいち実感できない…という方もいるかと思います.これは研究者でも同じで,同じ結果であっても,図示化してあげるだけで理解度はぐっと高まります.ここでは上記で得られた結果を図示化する方法について説明します.
今回のように結果変数Yと説明変数Xという2つの変数間の(線形な)関係のみをシンプルに推定しているような状況の可視化は簡単です.方法はいろいろとありますが,今回は seaborn というライブラリを利用します.seabornは変数の分布などを表現する際に非常に役立つライブラリです(公式).
seabornライブラリで2変数間の線形な関係を図示する際には jointplot 関数を使います.jointplot関数において結果変数yと説明変数xをそれぞれ指定すると,その2変数間の関係を表示してくれます.
# seabornライブラリを使える状態にする
import seaborn as sns
# outcome_numとtreat_numの線形な関係を可視化する
sns.jointplot(x="treat_num", y="outcome_num", data = df, kind = "reg", scatter = False)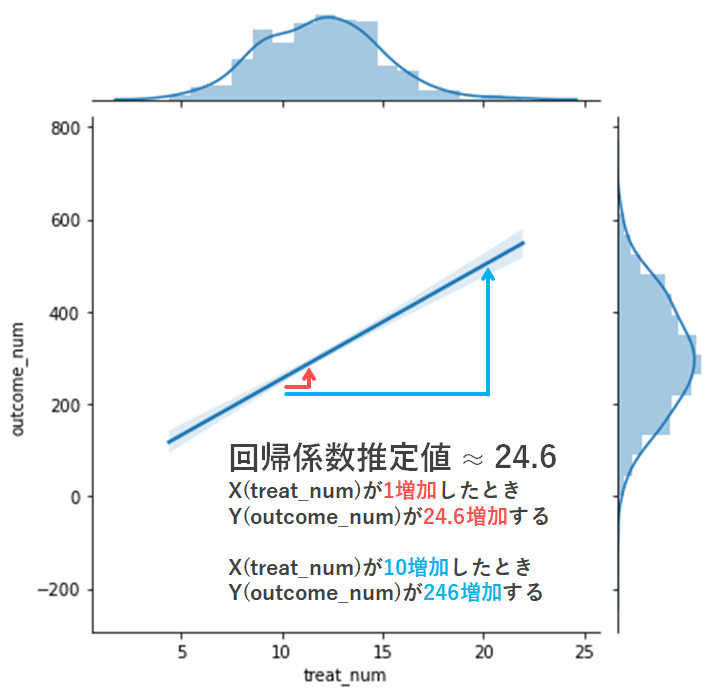
いかがでしょうか?図をみると2つの変数の関係性がより良く把握できそうですね.また上記で説明した回帰係数推定値の解釈についても,図にあわせて追記してみましたので,参考にしてみてください.
線形回帰モデルで予測された結果変数の値を表示
線形回帰モデルについて,XのYにおける影響力(あるいは両者の関係性)を知りたい場合は上記で説明した回帰係数推定値を確認すればOKですが,モデルによって結果変数Yの値を予測したいという場合もあります.モデルによって得られた予測値を取得する場合には,以下のコードを実行してください.ここでは予測値と一緒に,推定の誤差範囲を示す指標である95%信頼区間(lower=下限値,upper=上限値)も抽出しています.
# Yの予測値を取得
pred = results.get_prediction()
frame = pred.summary_frame(alpha=0.05)
frame["mean"]
frame["mean_ci_lower"]
frame["mean_ci_upper"]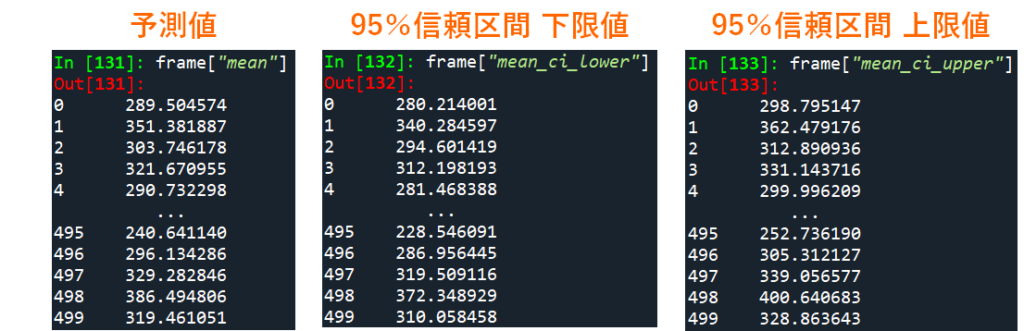
scikit learnライブラリで線形回帰分析
おまけに,scikit learnライブラリで線形回帰分析を実行する方法を紹介しておきます(公式).scikit learnライブラリはneural network系の手法も幅広く扱える非常に強力なライブラリではありますが,結果の表示方法などが少し初心者向けではないように思います.そのためこの記事ではおまけ的な扱いにしています.
どちらにせよ推定結果は同じですが,どうしてもscikit learnライブラリにこだわりたい!という方は,以下のコードを実行してもらえれば,上記のstatmodelsライブラリの結果と同じ回帰係数推定値などを得ることができます.
# scikit learnライブラリの線形回帰モデルを使える状態にする
from sklearn.linear_model import LinearRegression
# モデルの構築
ols = LinearRegression()
# 目的変数Yと説明変数X
Y = df[["outcome_num"]].values
X = df[["treat_num"]].values
# モデル推定
ols.fit(X,Y)
# 回帰係数を出力
ols.coef_まとめ
今回はPythonにおいて,statmodelsを利用した線形回帰分析の実行方法を紹介しました.線形回帰モデルは scikit learn パッケージなどでも実施可能ですが,statmodelsライブラリを使えばより簡単に結果のサマリーまで表示してくれるため,初心者にも非常におすすめです.
またRユーザーにとっても理解しやすい関数構造になっていると同時に,同時にscikit learnなどに慣れている人でも問題なく使えるように構築されています.
またPythonの実践的な使い方を体系的に学びたいという方は以下のスクールがおすすめです.以下の記事でこれらのスクールの比較も行っていますので,ぜひ参考にしてみてくださいね.



コメント