
記事の要約:pandasによるデータの要約と編集【図解】
この記事で学べること
- pandasライブラリとは?
- 解析に利用する基本的なデータの構造
- pandasを使ったデータ内容の確認・要約・編集方法
この記事のまとめ
- pandasとはpythonにおいてデータフレームを扱う基本ライブラリ
- データ(CSVやExcel)は基本的に1行目が変数名として用意しておく
- pandasでデータの読みこみから抽出や内容のサマリーができる
- 実務的なデータ編集作業はdpflyライブラリを使う方がおすすめ
pandasライブラリとは?
pandasライブラリは,pythonにおける代表的なライブラリの1つです.
pandasでは,ExcelやCSVなどで収集したデータを読みこんだり,データ内容を確認したり,解析前のデータクリーニングなどを行うことができます.
特徴としては,読みこんだデータをExcelやCSVと同じように「表」の形で扱うことができる点です.この表の形を「DataFrame型」と呼びます.DataFrame型を使えば,それぞれの列や行を明示的に指定して,解析や編集を行うことができます.
もちろんpandas以外のライブラリでも代用できる機能は沢山ありますが,pandasにおけるデータフレームの扱いは他のライブラリでも共通している,なんなら他の言語とも共通している部分ですので,ぜひここで勉強してみてください.
pandasでデータを要約
それでは早速データセットを読みこんで解析していきましょう.
python,Anaconda3をインストールした際に使えるようになるSpyderという環境で操作します.Python単体でも同様のスクリプトで実行可能ですが,Spyderにはいろいろな補助機能があるため,こちらを使っていきましょう.
データセットは練習用のCSVデータを準備しましたので,手元にちょうどよいデータがなければ,これらをダウンロードしてご利用ください.
| id | iv | cnf1 | cnf2 | ・・・ | outcome_num | outcome_skew | outcome_ord | time |
| 1 | 0 | 0.14 | 0 | ・・・ | 200.9 | 0 | 1 | 0.04 |
| 2 | 0 | 0.41 | 1 | ・・・ | 160.37 | 0 | 1 | 0.11 |
| 3 | 1 | -0.07 | 0 | ・・・ | 461.07 | 158.34 | 3 | 0.08 |
| 4 | 1 | -0.25 | 0 | ・・・ | 363.76 | 76.03 | 2 | 0.02 |
| 5 | 0 | 0.7 | 0 | ・・・ | 290.58 | 0 | 1 | 0.02 |
| ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ |
| 496 | 0 | -1.35 | 1 | ・・・ | 227.81 | 0 | 1 | 0.11 |
| 497 | 0 | 1.03 | 0 | ・・・ | 170.44 | 0 | 1 | 0.17 |
| 498 | 1 | -0.81 | 0 | ・・・ | 326.61 | 44.92 | 2 | 0.2 |
| 499 | 1 | 1.8 | 0 | ・・・ | 256.07 | 0 | 1 | 0.13 |
| 500 | 0 | 1.77 | 0 | ・・・ | 197.09 | 0 | 1 | 0 |
※11人目以降は省略
準備1.参考データ(CSV)をダウンロード
※後ほどSpyder上で読み込みたいデータの場所を指定する必要があるため,デスクトップなど自分が分かりやすい場所に保存しておくことをおすすめします!
準備2.Spyderを起動 ⇒ 新規ファイルを作成 ⇒ CSVファイルの読み込み
CSV・Excelファイルのpythonにおける読みこみ方は,以下で詳しく説明していますので,参考にしてみてください.今回はデータセットを df と名前をつけて読みこんでいます.
# pandasライブラリをpdを名前をつけて使える状態にする
import pandas as pd
# pdに含まれるread_csvというメゾッドを使ってデータを読みこみdfとして保存
# データの格納場所は適宜修正してください
df = pd.read_csv("/Users/USERNAME/Desktop/robustwife/robustwife_all.csv", encoding="utf-8") 
データの先頭と末尾だけをのぞき見る .head .tail
まずは読みこんだデータセットを部分的にのぞき見してみましょう.(厳密にデータ内容を確認する際にはスクリプトでロジックを組むのですが,一応,ちゃんと読みこめてるかざっくり目視したなることもあります…人間なので…)
この時に便利な関数が head と tail です.使い方は読みこんだデータセットの末尾に .head(先頭から表示する行数),.tail(末尾から表示する行数) を書き加えるだけです.ここでは先頭5行と末尾5行を表示させています.非常に簡単ですね.
# dfの先頭5行を抽出
df.head(5)
# dfの末尾5行を抽出
df.tail(5)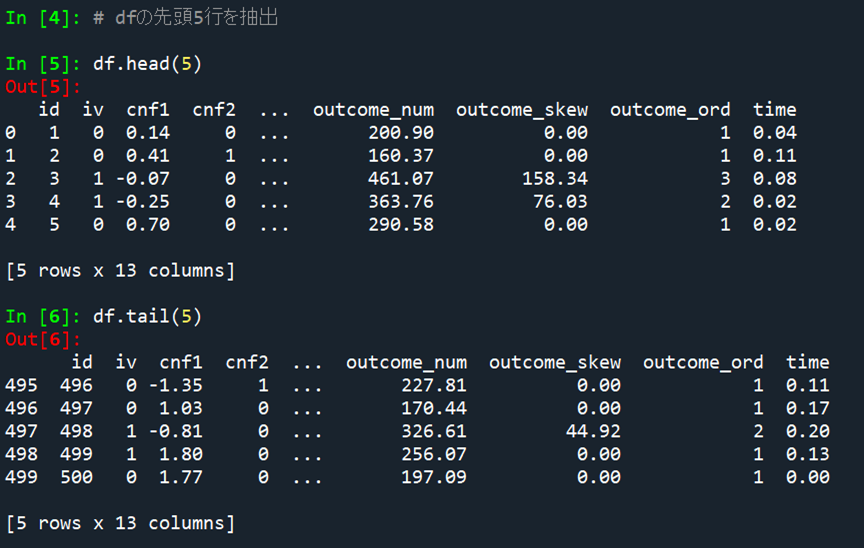
なおspyderの初期設定では列数や行数が多い場合には ・・・ で途中が省略されます.
データの構造=行数×列数を確認する .shape
pandasではデータを行と列からなる表の形で扱うと説明しました.ここでは読みこんだデータが,難行・何列の構造・大きさのものであるのかを確認しておきましょう.
この時に使う関数が shape です.使い方は読みこんだデータセットの末尾に .shape を書き加えるだけです.結果は (行数, 列数) という形で表示されます.データフレームを扱うときには基本的にどの言語でも,「行→列」の順番で表示されることが多いので,感覚的に覚えておいてください.
# データの形・型を確認
df.shape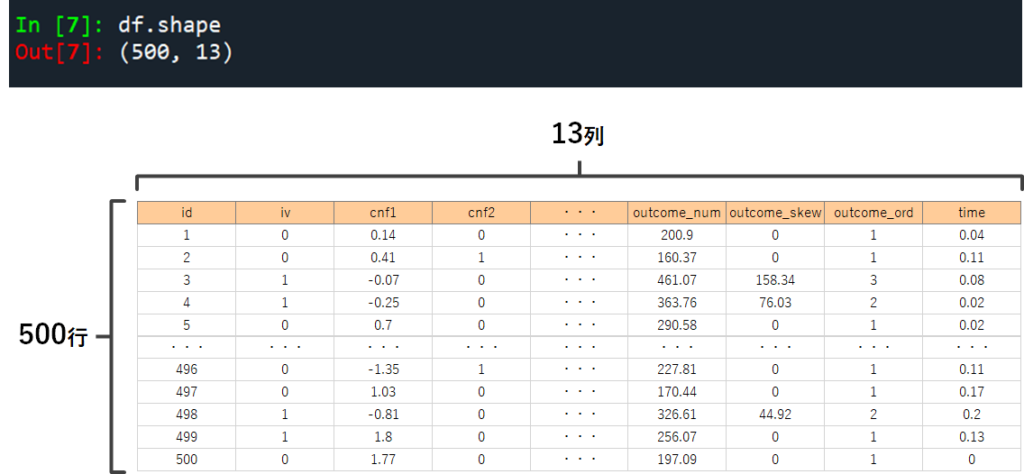
変数名=列名を表示する .columns
データを利用した解析では,年齢や性別など,1種類の変数を1つの列にまとめます.ここでは読みこんだデータが持っている変数の名前(=列の名前)を全て表示させてみましょう.
この時に使う関数が columns です.使い方は読みこんだデータセットの末尾に .colmuns を書き加えるだけです.全ての変数名が表示されます.データ解析では変数の名前を指定して使いますので,変数名の確認方法は慣れておきましょう.
また少し発展的な内容として,.columns.values と付記すると,変数名がリスト形式で抽出できます.これが出来ると便利なことが色々とあるのです紹介しましたが,現時点で変数名を確認する目的だけであれば,特に覚えておく必要はありません.
# 列名(変数名)を確認
df.columns # インデックスオブジェクトで表示
df.columns.values # リストで表示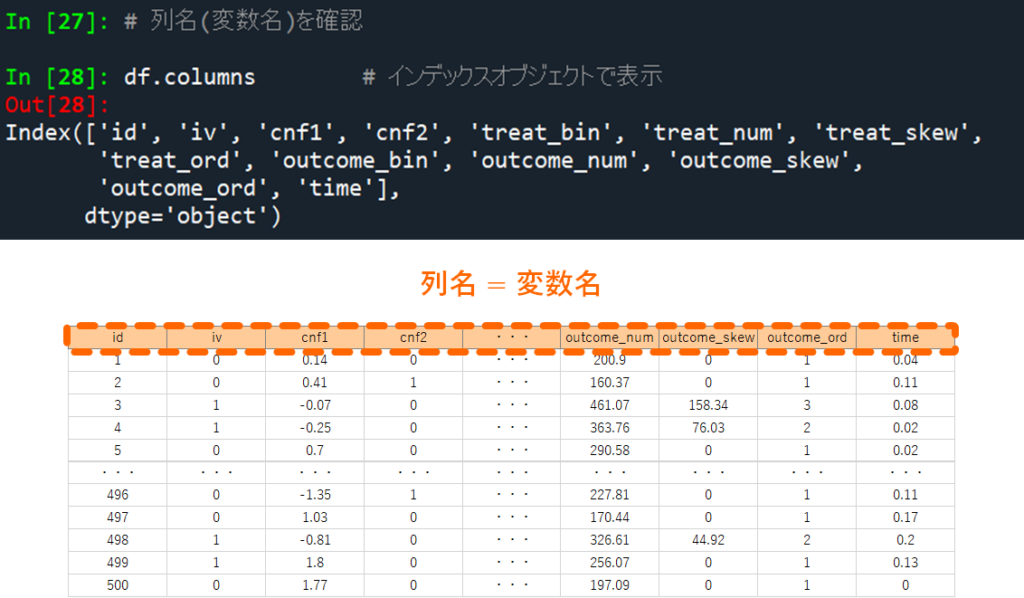
全ての変数についてヒストグラムを描く(超便利).hist()
次は各変数に含まれる要素を視覚的にとらえられるようにしてみましょう.今回は各変数ごとにヒストグラム(各要素の数がどれくらいか?という棒グラフを並べたものだと思ってください)を書いてみます.
この時に使う関数が hist です.使い方は読みこんだデータセットの末尾に .hist(figsize = (横サイズ,縦サイズ)) を書き加えるだけです.全ての変数についてヒストグラムが表示されます.サイズには数値を入力しますが,読みこんだデータに含まれている変数の種類が多いようであれば,サイズ数を大きくしてください.
# 全ての変数についてヒストグラムを作成
df.hist(figsize = (12,12))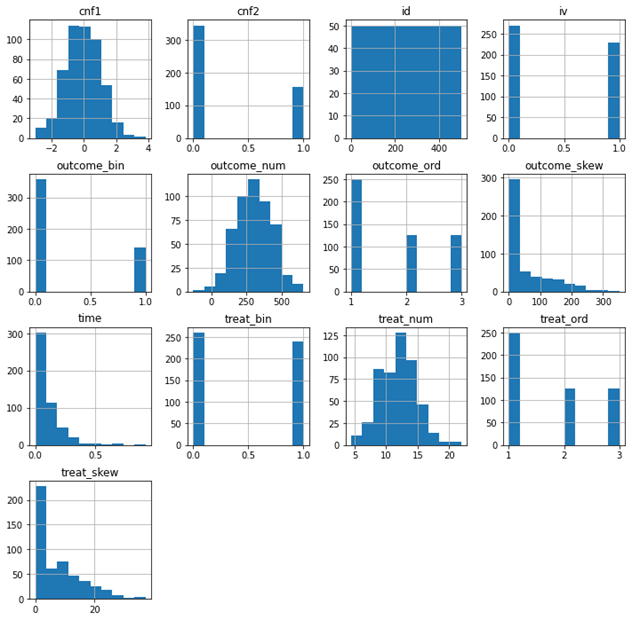
全ての変数について要約値を計算する(超便利).describe()
次は各変数に含まれる要素を数値として要約してみましょう.
この時に使う関数が describe です.使い方は読みこんだデータセットの末尾に .describe() を書き加えるだけです.全ての変数について要約した統計量(データ数 count,平均 mean, 標準偏差 std, 最小値 min, 第一四分位点 25%, 第二四分位点 50%, 第三四分位点 75%, 最大値 max)が表示されます.
# 各変変数の要約
df.describe() # 基本的な要約量をすべて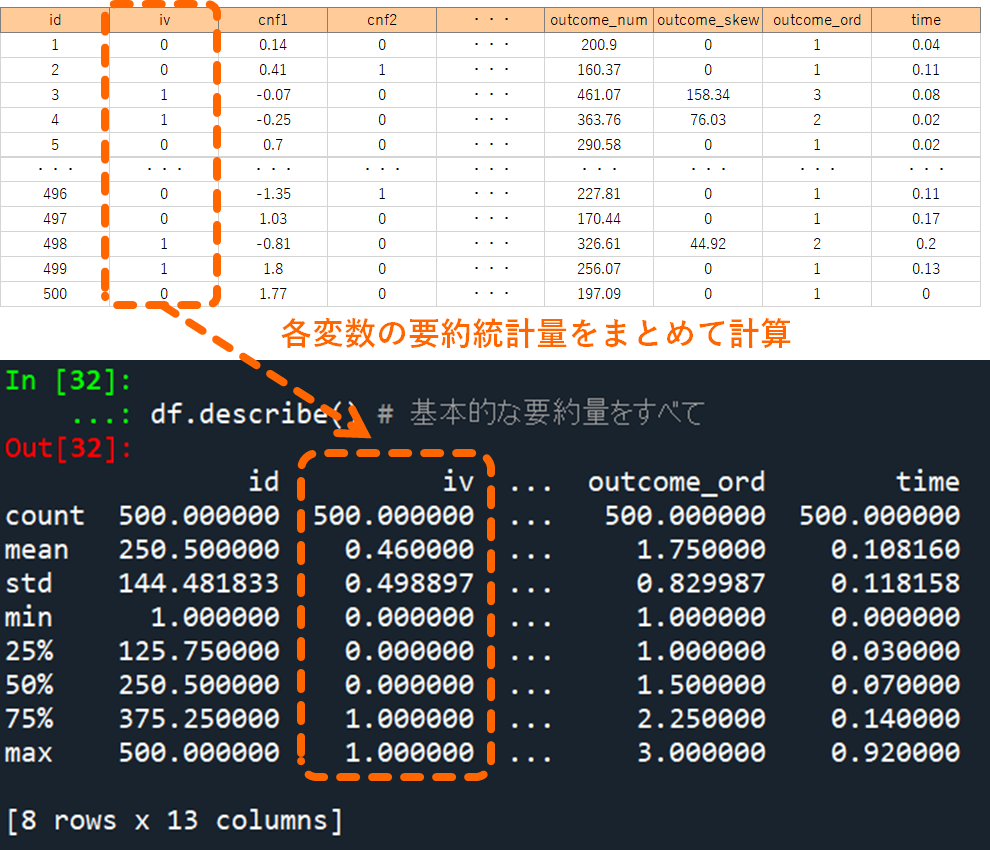
describeを使えば全ての要約値が得られますが,それぞれの値を個別に計算したい場合には,以下のような関数が用意されています.とても簡単ですよね.
df.sum() # 合計
df.mean() # 平均
df.median() # 中央値
df.quantile(0.25) # 25%点(第1四分位点)
df.quantile(0.50) # 50%点(第2四分位点)
df.quantile(0.75) # 75%点(第3四分位点)pandasでデータを編集
データフレームから特定の行・列を抽出する
データ解析や前処理を行う際には,それぞれの変数(列)を抽出して再定義したり,特定の対象者(男性など)に該当する行のみを抽出してサブグループデータを作成したりすることがあります.これらのデータの抽出はデータ解析の必修科目なので,ここで基本を押さえておきましょう.
データフレームから特定の列を抽出する方法は3通りあります.
- データフレーム[“変数名”]
- データフレーム.loc[“行名”, “列名”]
- データフレーム.iloc[行数, 列数]
また複数の列をしているする際には,以下のように複数の要素を [] で囲ってください.
- データフレーム[[“変数名1”, “変数名2”]]
- データフレーム.loc[[“行名1”, “行名2”], [“列名1”, “列名2”]]
- データフレーム.iloc[[“行数1”, “行数2”], [“列数1”, “列数2”]]
行数や列数を指定せず全て抽出する場合には : を入力します.

また複数の行数・列数を 始まり番号:終わり番号 のように指定することができます.この場合の注意点として「終わり番号の1つ手前」までが表示されることを覚えておいてください.

各変数(列)を取り出す
df["iv"] # ひとつの変数を取り出す
df.iv # ひとつの変数を取り出す省略ver.
df[["cnf1", "cnf2"]] # 複数の変数を取り出す
# loc -> 行・列"名"を指定して取り出す
df.loc[:, "iv"] # 全ての行・iv列を取り出す
df.loc[:, ["cnf1","cnf2"]] # 全ての行・cnf1/cnf2列を取り出す
df.loc[:, "iv":"cnf2"] # 全ての行・ivからcnf2までの列を取り出す
# iloc -> 行・列"数"を指定して取り出す
df.iloc[:, 3] # 全ての行・2番目の列を取り出す
df.iloc[:, [2,3]] # 全ての行・3/4番目の列を取り出す
df.iloc[:, 1:4] # 全ての行・2~4番目までの列を取り出す各要素をカウントする .value_counts()
次は特定の変数に含まれる要素をカウントしてみましょう.
この時に使う関数が value_countです.使い方は読みこんだデータセットの末尾に .value_counts() を書き加えるだけです.変数の中に含まれる各要素がどれだけあるのかカウントを見ることができます.
# 各要素のカウント
df["iv"].value_counts()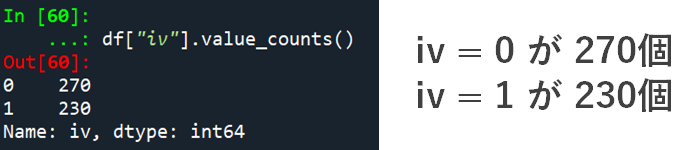
条件にあてはまる要素を抽出
次は特定の条件に当てはまるデータのみを抽出してみましょう.変数の中の各要素が特定の条件に当てはまるかどうかを確認するスクリプトのことを条件式と呼びます.pythonで使われる条件式には以下のようなものがあります(他の言語でも似たようなものです).
| 条件 | 条件式スクリプト |
| aとbは等しい | a == b |
| aとbは等しくない | a != b |
| aはbより大きい | a > b |
| aはb以上 | a >= b |
| aはbより小さい | a < b |
| aはb以下 | a <= b |
| ※TrueとFalseを入れ替える | ~(条件式) |
| ※a=b かつ a=c | (a==b) & (a==c) |
| ※a=b または a=c | (a==b) | (a==c) |
これらの条件に当てはまる場合は True を,当てはまらない場合には False を返します.このTrueとFalseをブール値とよびます.
# 特定の条件にあてはまるかどうかの確認(真義値=bool型)
# 当てはまる -> True
# 当てはまらない -> False
iv = df["iv"]
iv
iv==1 # 1と一致する場合はTrue/一致しない場合はFalse
iv!=1 # 1と一致しない場合はTrue/一致する場合はFalse
~(iv==1) # 1と一致しない場合はTrue/一致する場合はFalse
iv>0 # 0より大きい場合はTrue/0以下の場合はFalse (< の場合はその逆)
iv>=0 # 0以上の場合はTrue/0未満の場合はFalse (<= の場合はその逆)
# 複数の条件
(iv==0) & (iv>0) # 0と等しい かつ 0より大きい -> 全てFalse
(iv==1) | (iv==0) # 1と等しい あるいは 0と等しい -> 全てTrue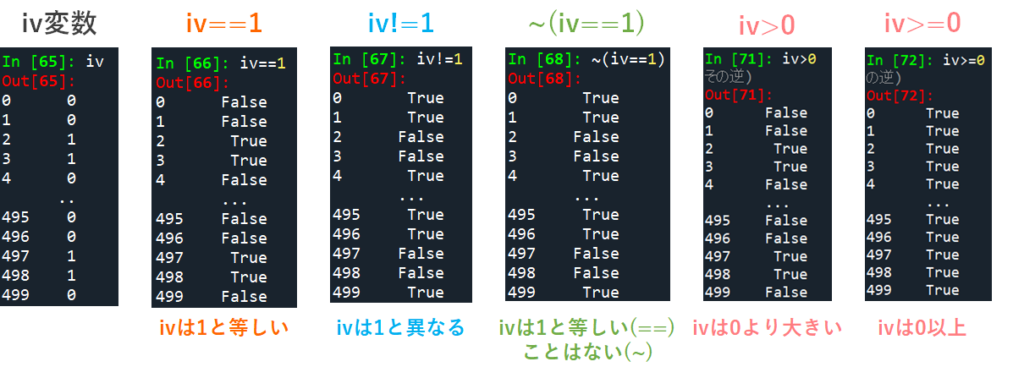
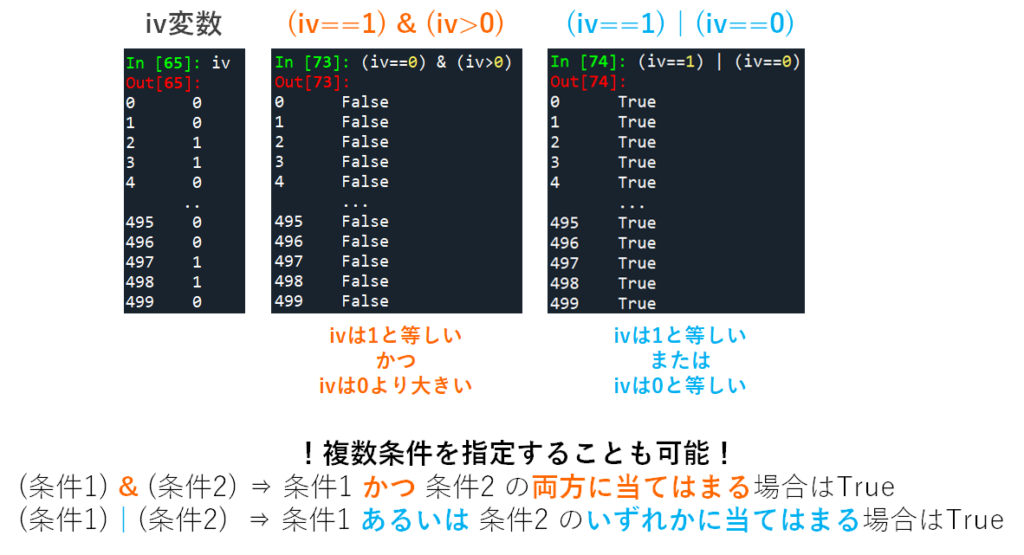
このTrueとFalseからなるブール値を使って,一部のデータを抽出することも可能です.例として,変数ivの各要素が条件式にあてはまる(True)行のみをdfデータから抽出してdf1として保存してみましょう.
# -> Trueに該当する行だけを取得する
df1 = df[iv==1]
df1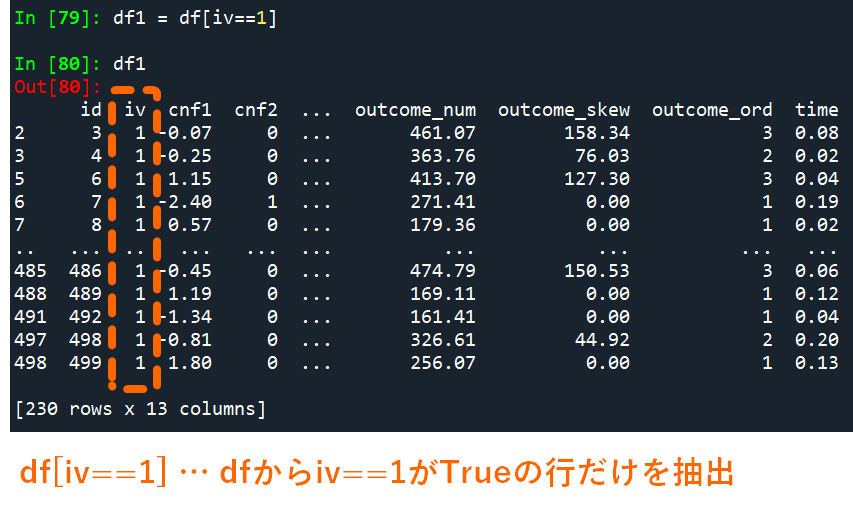
新しい変数の作成 & 条件分岐
データフレームに新しい変数を追加する
最後に,データに新しい変数を追加する方法について基本を解説します.データに新しい変数を追加する際には以下のスクリプトを使います.
データセット[“変数名”] = 追加する要素
追加する要素は原則データセットの行数と一致している必要があるのですが,もし追加する要素が以下の例のように1つ(”ADD”)しかないような場合には,全ての行に同じ要素が入力されます.また基本的に新しい変数は右端に追加されていきます.
# 新しい変数(列)を作成
df["add"] = "ADD"
df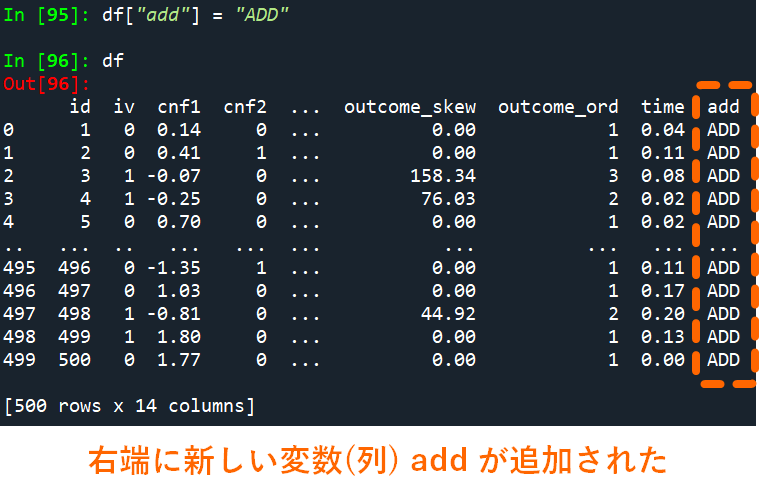
条件式を使って新しい変数を作る
次は,条件式をつかって,特定の条件に当てはまる要素だけを修正してみましょう.これは実際のデータ解析でも非常によく使う方法なので,ぜひここで身に着けておきましょう.
以下の例では,データdf内の変数ivについて,1→”Treated”,0→”Untreated”という置き換えを行い,その結果を新しい変数iv_labとしてデータ内に追加しています.
# 条件分岐をして新しい変数の作成
# -> もっと複雑な条件分岐なども可能だけど結構大変
# -> dfplyなどほか関数を使うのが一番実用的(だと思っている)なので別記事で紹介
df.loc[df["iv"]==1, "iv_lab"] = "Treated"
df # iv=1の時はiv_labがTreatedになる(それ以外はNaN)
df.loc[df["iv"]==0, "iv_lab"] = "Untreated"
df # iv=0の時はiv_labがUntreatedになる(それ以外はNaN)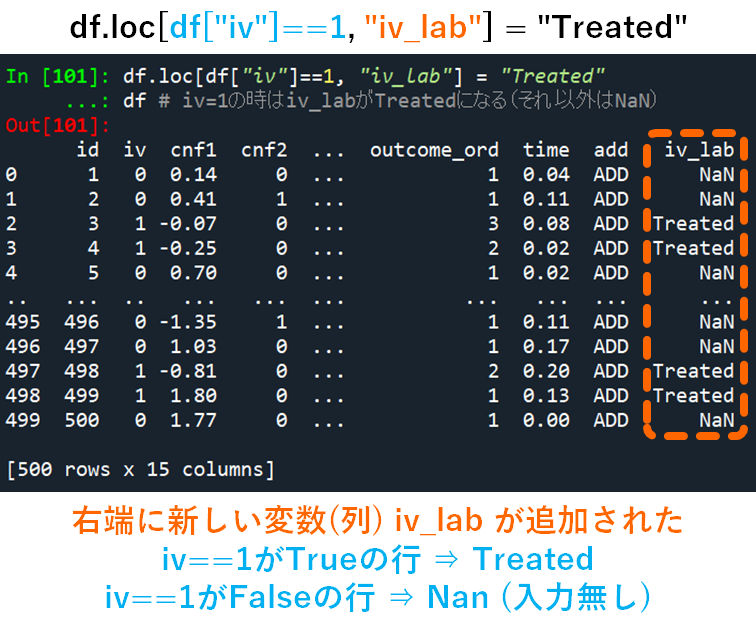
まずはiv==1の場合にはiv_labに”Treated”が入力されました.この段階ではiv==0の場合について何も指定していないので,NaN (Not a Number) が入力されます.つまり何も値が入っていないよということです.
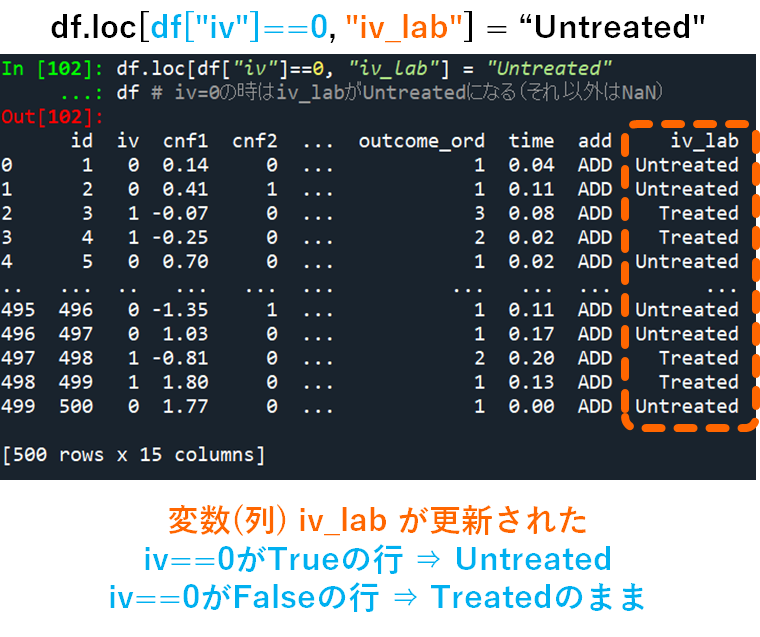
これで,iv==0の場合について,”Untreated”が入力されました.
変数の内容を置換
最後に,変数内容を簡単に上書きする方法を説明しておきます.ここでは,先ほど作成した iv_lab の内容について,Treated → Invervension,Untreated → Control に置き換えてみます.
この時に使う関数が replace です.使い方は,
データ[“変数名”].replace([“置換前の要素1”, “置換前の要素2”], [“置換後の要素1”, “置換後の要素2”])
を書き込むだけです.”置換前の要素1″が”置換後の要素1″,”置換前の要素2″が”置換後の要素2″に置き換えられます.
# 変数内容を置換
df["iv_lab"].replace(["Treated", "Untreated"], ["Intervention", "Cntrol"], inplace=True)
df # iv_labの変数内容が変更された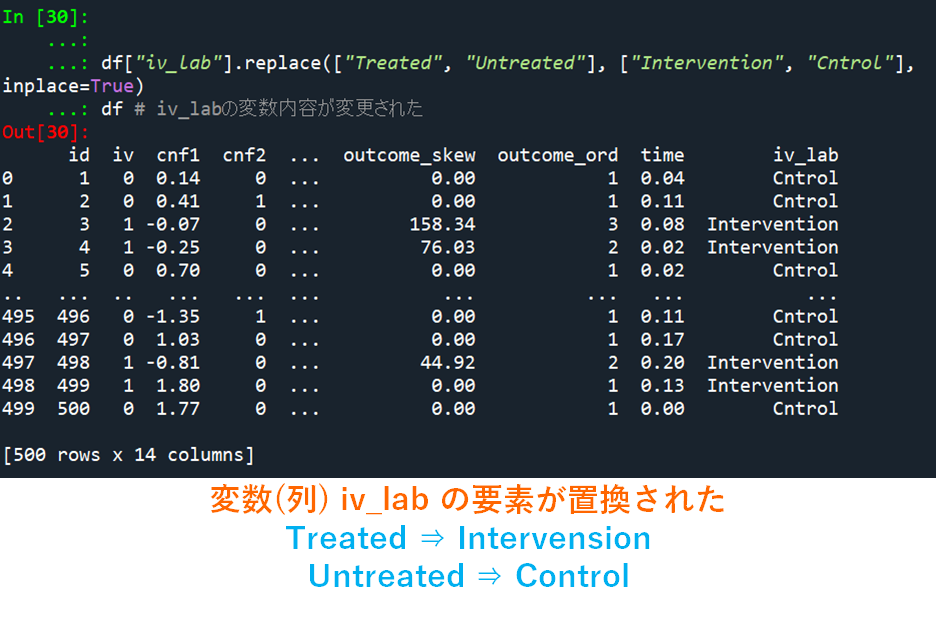
これは余談ですが,実際に業務レベルで非常に多くの変数を複雑に操作しようとすると,pandasライブラリだけで対処するのは結構大変です.他にもデータを編集するためのライブラリは存在するのですが,その中でもおススメかつ信頼できるライブラリが dfply です.dfplyを利用したデータの編集方法については,以下の記事で紹介していますので,ぜひ参考にしてみてください!
まとめ
今回はPythonにおいて,pandasを利用したデータ内容の確認および編集方法についての基本を紹介しました.pandasライブラリはpythonを用いた解析においてほぼ必ず目にするもなので,使い方を覚えておいて損はありません.この記事が参考になれば幸いです.
またPythonの実践的な使い方を体系的に学びたいという方は以下のスクールがおすすめです.以下の記事でこれらのスクールの比較も行っていますので,ぜひ参考にしてみてくださいね.



コメント