
記事の要約:dfplyによるデータの編集(前処理)【図解】
この記事で学べること
- dfplyライブラリとは?
- dfplyを使ったデータ内容の確認・要約・編集方法
この記事のまとめ
- dfplyとはデータフレームを直感的に編集できる超便利ライブラリ
- Rのdplyrパッケージと同じ使い方ができるためRユーザーにも優しい
- 実務的なデータ編集作業はdpflyライブラリがおすすめ
dfplyライブラリとは?
dfplyライブラリは,pythonにおいてデータフレームを直感的に編集できるライブラリです(公式).
pythonでデータフレームを扱うときは,基本的にpandasライブラリを使うことが多いかもしれません.しかしpandasは扱い方に少しクセがあり,実際の業務でも,データの前処理をもう少し直感的かつスムーズにできないかと思うことも少なくありません.
dfplyはそんな悩みを解消してくれる素敵なライブラリです.メリットとして以下が挙げられます.
- データの編集過程を明示的に重ねていくため直感的で分かり易い
- データ解析の実務において「これやりたいな」がだいたい出来る
- Rのdplyrパッケージと同じことが可能なのでRユーザーにも使いやすい
非常に使いやすいライブラリですので,これからPythonを学ぶ方もぜひ取り入れてみてください.それでは早速,dfplyの基本的な使い方を見ていきましょう.
dfplyライブラリのインストール
Pythonでは各ライブラリは事前にインストールしておく必要があります.一般的によく使われるpandasやnumpy等はAnaconda経由でpythonをインストールした時点で既に自動でインストールされていますが,dfplyライブラリはデフォルトの設定ではインストールされていません.
そのため,まずはdfplyライブラリのインストールから始めましょう.ちなみにこのライブラリをインストールする手順は,他のライブラリでも同じですので,この機会にぜひ手順を覚えておきましょう.
手順1.Anaconda Prompt (anaconda)
手順2.プロンプト内に以下をペーストしてEnter
pip install dfply手順3.Successfully installed dfply-# のメッセージがでたら完了
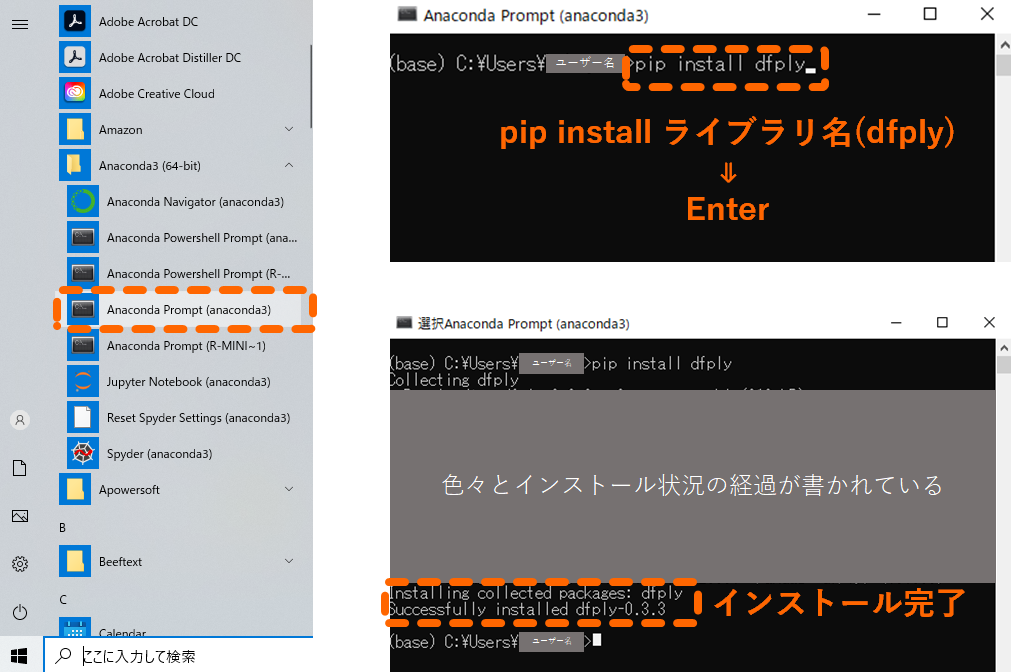
これでdfplyがPythonで使えるようになりました.とても簡単ですね!
dfplyでデータの編集
それでは早速データセットを読みこんで解析していきましょう.
python,Anaconda3をインストールした際に使えるようになるSpyderという環境で操作します.Python単体でも同様のスクリプトで実行可能ですが,Spyderにはいろいろな補助機能があるため,こちらを使っていきましょう.
データセットは練習用のCSVデータを準備しましたので,手元にちょうどよいデータがなければ,これらをダウンロードしてご利用ください.
| id | iv | cnf1 | cnf2 | ・・・ | outcome_num | outcome_skew | outcome_ord | time |
| 1 | 0 | 0.14 | 0 | ・・・ | 200.9 | 0 | 1 | 0.04 |
| 2 | 0 | 0.41 | 1 | ・・・ | 160.37 | 0 | 1 | 0.11 |
| 3 | 1 | -0.07 | 0 | ・・・ | 461.07 | 158.34 | 3 | 0.08 |
| 4 | 1 | -0.25 | 0 | ・・・ | 363.76 | 76.03 | 2 | 0.02 |
| 5 | 0 | 0.7 | 0 | ・・・ | 290.58 | 0 | 1 | 0.02 |
| ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ |
| 496 | 0 | -1.35 | 1 | ・・・ | 227.81 | 0 | 1 | 0.11 |
| 497 | 0 | 1.03 | 0 | ・・・ | 170.44 | 0 | 1 | 0.17 |
| 498 | 1 | -0.81 | 0 | ・・・ | 326.61 | 44.92 | 2 | 0.2 |
| 499 | 1 | 1.8 | 0 | ・・・ | 256.07 | 0 | 1 | 0.13 |
| 500 | 0 | 1.77 | 0 | ・・・ | 197.09 | 0 | 1 | 0 |
※11人目以降は省略
準備1.参考データ(CSV)をダウンロード
※後ほどSpyder上で読み込みたいデータの場所を指定する必要があるため,デスクトップなど自分が分かりやすい場所に保存しておくことをおすすめします!
準備2.Spyderを起動 ⇒ 新規ファイルを作成 ⇒ CSVファイルの読み込み
CSV・Excelファイルのpythonにおける読みこみ方は,以下で詳しく説明していますので,参考にしてみてください.今回はデータセットを df と名前をつけて読みこんでいます.
# pandasライブラリをpdを名前をつけて使える状態にする
import pandas as pd
# pdに含まれるread_csvというメゾッドを使ってデータを読みこみdfとして保存
# データの格納場所は適宜修正してください
df = pd.read_csv("/Users/USERNAME/Desktop/robustwife/robustwife_all.csv", encoding="utf-8") 
データフレームから特定の列を抽出する select
データ解析や前処理を行う際には,それぞれの変数(列)を抽出して再定義したり,特定の対象者(男性など)に該当する行のみを抽出してサブグループデータを作成したりすることがあります.pandasでも同じ作業は比較的簡単に行えますが,dplyrもルールはあまり変わりません.
dfplyで特定の列を抽出する際には select 関数を使います.dfplyではそれぞれの関数を使う場合に,データと関数を >> (パイプ演算子) で繋ぎます.ちなみにRのdplyrではパイプ演算子として%>%を使います.ちょっと特殊に思われるかもしれませんが,のちに説明する通りパイプ演算子を使うことで,データの編集過程をどんどん積み重ねていくことができます.
データフレームから特定の列を抽出する方法は3通りあります.
- データフレーム >> select(列番号)
- データフレーム >> select([“列名”])
- データフレーム >> select(X.変数名)
また複数の列をしているする際には,以下のように要素の間を , で区切ってください.
- データフレーム >> select([列番号1, 列番号2])
- データフレーム >> select([“列名1”, “列名1”])
- データフレーム >> select(X.変数名1, X.変数名2)
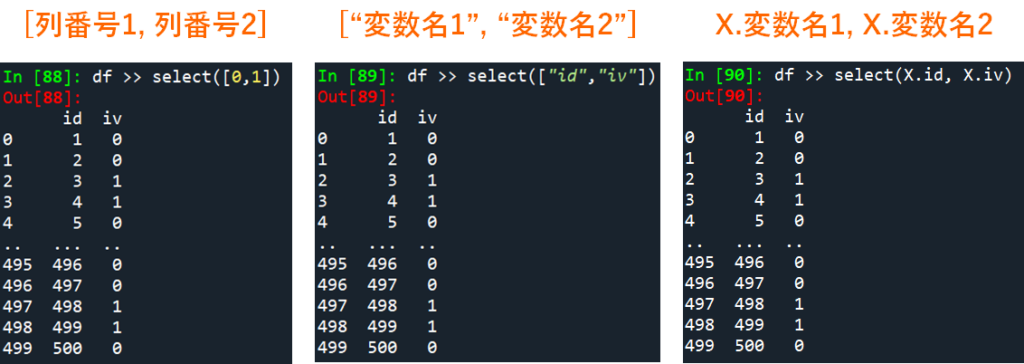
# select: 各変数(列)を取り出す
df >> select(0) # 列番号
df >> select(["id"]) # リスト
df >> select(X.id) # X.変数名
df >> select([0,1])
df >> select(["id","iv"])
df >> select(X.id, X.iv)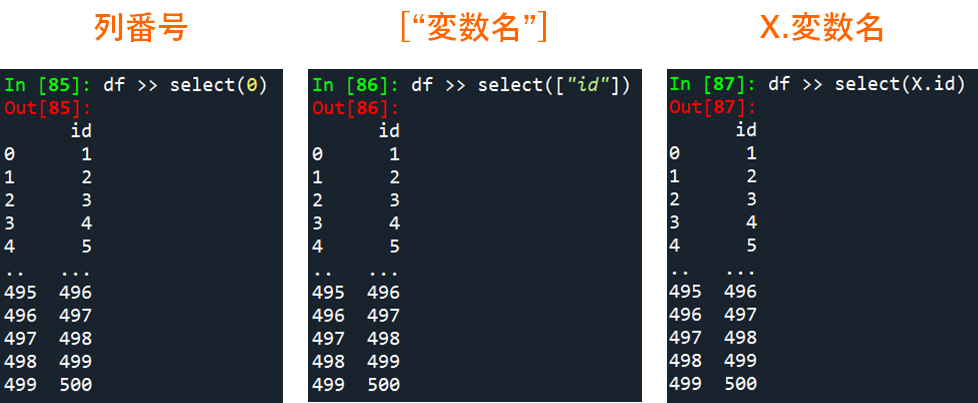
ちなみにPython上でのデータフレームの行・列の数え方については,以下の記事で図解しています.

データフレームから特定の列を除外する drop
次は特定の変数をデータから削除してみましょう.データフレームから特定の列を削除する方法は2通りあります.
- データフレーム >> select(~X.変数名)
- データフレーム >> drop(X.変数名)
関数で使い分けをしたいひとはdropを使えば問題ありませんが,変数の抽出・除外は全てselectで統一したい!というひとは ~ を変数名に添えてあげるだけでOKです.
# 不要な変数を除外する(この時点ではdfを上書きしない)
df >> select(~X.id, ~X.iv)
df >> drop(X.id, X.iv)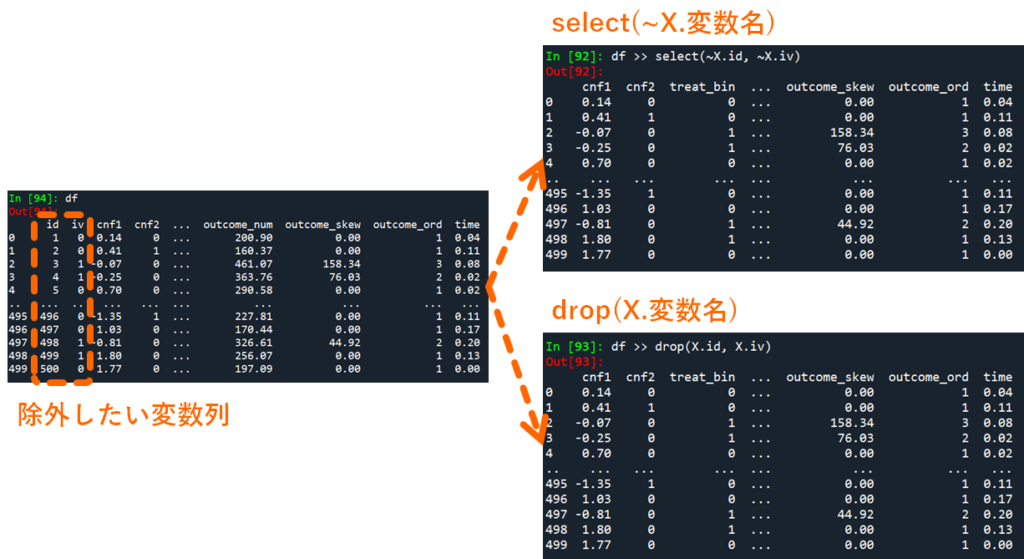
条件にあてはまる要素を抽出 filter_by
次は特定の条件に当てはまる行のみを抽出してみましょう.変数の中の各要素が特定の条件に当てはまるかどうかを確認するスクリプトのことを条件式と呼びます.pythonで使われる条件式などについては,以下の記事でまとめていますので参考にしてみてください.
dfplyで特定の条件に該当する行だけを抽出するときには filter_by(条件式) を利用します.以下の例ではデータ中の変数ivが1に該当する行だけを抽出しています.(抽出したデータはどこにも格納していないので,データ自体は更新されていません.)
# データ行の部分抽出
df >> filter_by(iv==1)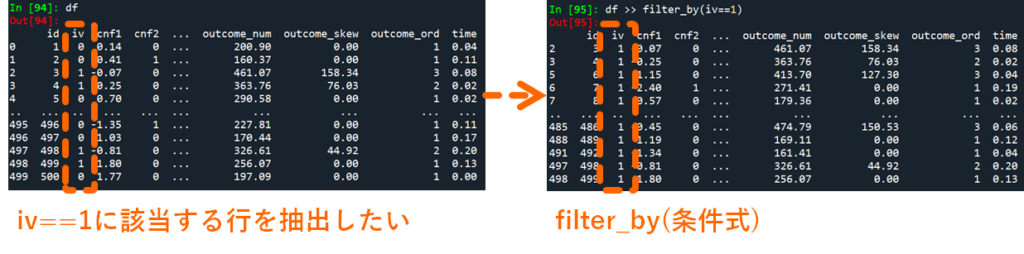
データの並べ替え arrange
次はデータの並べ替えをしてみましょう.データの並べ替えはデータを整理する目的だけでなく,同じIDをもつ対象者から複数回データが取得されているようなデータを扱うときにも非常に役立ちます.初学者の方はそのようなデータに触れる機会は少ないかもしれませんが,よく使うものなのでここで覚えておきましょう.
dfplyでデータを並べ替えるときには arrange(X.変数名) を利用します.以下の例ではデータ中の変数ivについて,昇順に並べ変えています.もちろんそれに伴って他の列も並べかえられています.(ここでも並べ替えたデータはどこにも格納していないので,データ自体は更新されていません.)
もし複数の条件でならべ変えたい時には arrange(X.変数名1, X.変数名2) というように入力します.すると,変数1についてまず並べ替え,変数1の各要素(0か1)をもつ行の中でさらに変数2について並べ替えを行うということができます.今回はivについて並べ替え,その中でさらにcnf1について並べ替えています.
# データの並べ替え
df >> arrange(X.iv) # 1つの変数で並べ替え
df >> arrange(X.iv, X.cnf1) # 2つ以上の変数で並べ替え
新しい変数の作成 & 条件分岐 mutate & if_else
最後に,データに新しい変数を追加する方法について基本を解説します.データに新しい変数を追加する際には mutate を使います.
mutate(新しい変数名 = 追加する変数の要素)
追加する要素の数は原則データセットの行数と一致している必要があるのですが,もし追加する要素が以下の例のように1つしかないような場合には,全ての行に同じ要素が入力されます.また基本的に新しい変数は右端に追加されていきます.
さらに以下のように条件分岐 if_else と併用して,既存の変数から新しい変数を作成するという作業も実務では良く行われます.
mutate(新しい変数名 = if_else(条件式, TRUEの場合の代入値, FALSEの場合の代入値))
if_elseは,以下の例のように条件式に X.treat_bin==1 が入力されていた場合,データdf中のtreat_binが1の場合にはTRUEの場合の代入値(“Treated”)を返し,1以外の場合にはFALSEの場合の代入値(“Untreated”)を返します.
※長いコードを1行に記載すると可読性が下がるため,3-4行目のように改行を行うことがあります.ここではtreat_labとsexという変数を作成するところで改行しています.ただしpython上では行が変わると異なる命令とみなされてしまうので,バックスラッシュを記載してから改行します.
# 新しい変数の追加
df >> mutate(treat_lab = if_else(X.treat_bin==1, "Treated", "Untreated"))
df >> mutate(treat_lab = if_else(X.treat_bin==1, "Treated", "Untreated"), \
sex = if_else(X.cnf2==1, "Male", "Female"))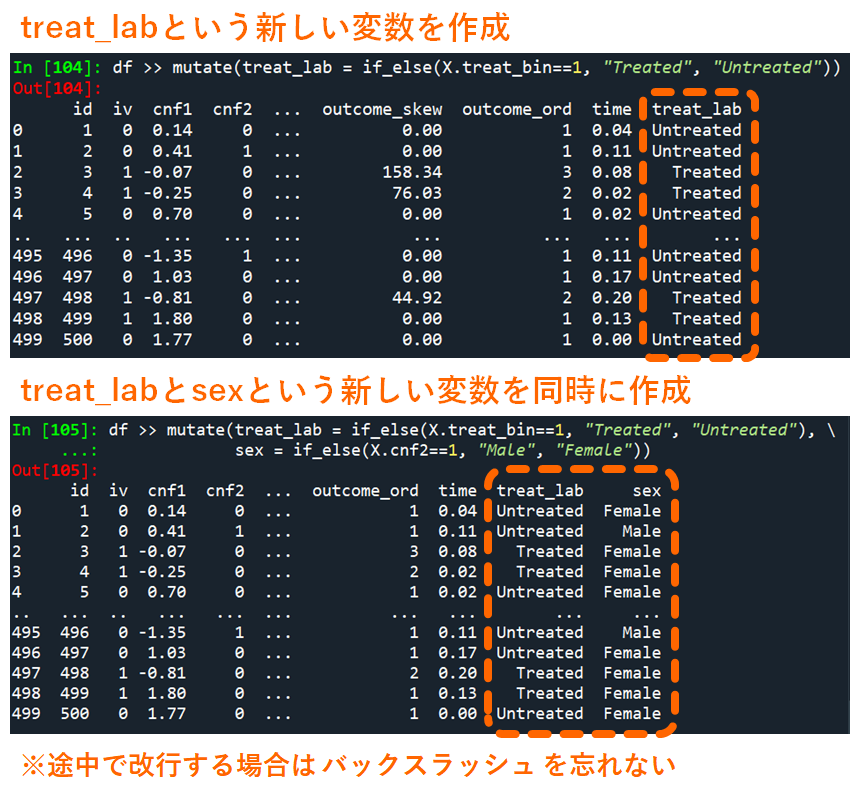
複数の関数をつなげて実行 → 新しいデータを作る
dfplyの優れたところは,上記で紹介した複数の関数をどんどんつなげて(追加して)いけるところです.非常に可読性が高く,ミスも少なくなりますので,ぜひ活用してみてください.
それでは早速,データdfに対して上記で紹介した操作をつなげて実行し,newという新しいデータをつくってみましょう.作業としては,1つ前の関数の末尾に,次の関数をパイプ演算子でつなげていくだけなので簡単です.
なお以下の例でも,関数をつなげるところで改行しておきたいので,パイプ演算子>>の後にバックスラッシュを追加しています.
# treat_labとsexを作成 -> sex=Femaleを抽出 -> id, sex, treat_lab 列のみを取り出す
# -> 改行するときには \ が必要
new = df >> \
mutate(treat_lab = if_else(X.treat_bin==1, "Treated", "Untreated"), \
sex = if_else(X.cnf2==1, "Male", "Female")) >> \
filter_by(X.sex=="Female") >> \
select(X.id, X.sex, X.treat_lab)
new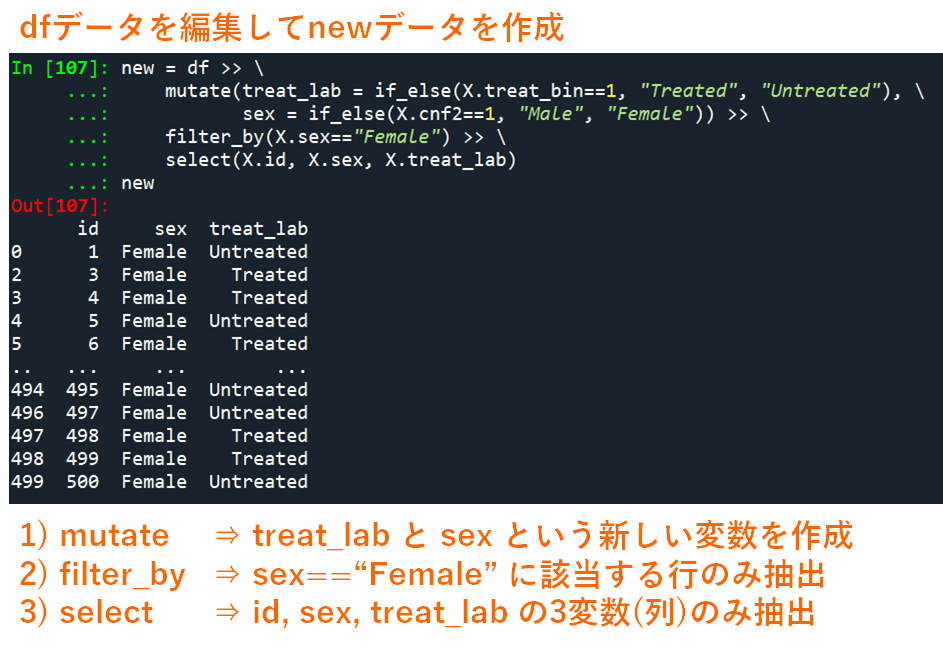
まとめ
今回はPythonにおいて,dfplyを利用したデータの編集方法について紹介しました.pandasライブラリだけだとデータ編集・前処理が少し手間…というときにも,dfplyを使えば直感的にデータを操作することができるのでおすすめです.
またRユーザーにとっても理解しやすい関数構造になっていますし,Rではdplyrというパッケージでほとんど同じことが実行できますので,RとPythonの両方を使っているよという方にもおすすめです.
またPythonの実践的な使い方を体系的に学びたいという方は以下のスクールがおすすめです.以下の記事でこれらのスクールの比較も行っていますので,ぜひ参考にしてみてくださいね.



コメント